Abstract
The data is an important asset for every organization, enterprises, and businesses in each field. With the increase in businesses and the number of organizations across the world, the volume of data has also increased that raise the security and storing issues. The Big Data environment is a great profit to the business, organizations and many small- or large-scale industries. The high volume of data cannot be handled using existing or traditional tools and techniques. Therefore, new and feasible data storage system has invented, named Big Data. Although, the Big Data technology able to store the high volume of data, but it has originated issues such as security and confidentiality of data. In the way to attain an overall outlook of the Big Data issues and problems, the research is focused to bring out an examination with the unbiased of prominence the main challenges concerning the Big Data security. Further, a number of solutions are proposed by the numerous literature to solve the security challenges in the Big Data. It is nearly impossible to carry out thorough research into the topic of security challenges in the Big Data. Hence, a large picture of the main security challenges related to the Big Data system with its principle solutions is proposed in the thesis.
Chapter 1
Introductions
In the past few years, data has become the most important possessions for each company in every field. The data has not only important for the company that based on computer science but they also for companies such as, the government of the country, healthcare, engineering sector and in the education sector. The data are also essential with the esteem to carrying out their regular activities and further assisting the business management in meeting their targets and carrying out the decision that is useful to them, by their collected information and which has extracted from them. It has been seen that the volume of data has enhanced dramatically in the previous years. Reportedly, 90% of the data has been generated in the last decade. Approximately 5 Exabyte’s of the data has creased by the peoples in the year 2003 (Jakóbik 2016).
Shortly, the volume of data will be increased due to high dependency on the advanced types of machinery such as multimedia, social media, and the various IoTs and these technologies are also producing an irresistible flow of data. In the period of the Big Data technology, the majority of data is unstructured and is hard to calculate the data using the existing system because traditional systems are not capable of analyzing such a high volume of data. Companies that are having their data stored on the clouds, they are keen to extract more advantageous data from verity and high volume of data. With the implementation of troublesome technologies, issues are also increased with it. In Big Data environment, the problems are related to the variety or volume of the big data, data privacy, quality, and security. The thesis is focused on the security tests that related to the Big Data technology. The Big Data technology not only increases the chances of being attacked by the threat agents but also introduce new challenges that need to be overcome in the new and feasible way. As the Big Data has numerous organization’s or government’s data, therefore, more regulations are required to eliminate these security issues. Furthermore, achieving the height of integrity and security of Big Data has become a barrier that would lower down the speed of technology. Therefore, the Big Data technology will lose the trust that could require a level of trust (Amin 2015).
There are four different characteristics of Big Data security as per the principles. These are data privacy, data integrity, infrastructure security, and data management. These principle-based characterizations used by the IOS (International Organization for Standardization) in the way to create security standards.
The thesis is aimed to highlight the critical security issues that might affect the Big Data. The overview of security issues would help other researchers to understand better the security concerns associated with the Big Data environment. The aim has been successfully achieved by introducing some studies and methods that are focused on the elimination of security issues (Savas & Deng 2017).
Research Questions:
- What are the major security challenges related to the adoption of Big Data Strategy?
Classification of various security challenges will help to get knowledge about the different areas that needs to be focused for eliminating the various security challenges associated with the Big Data strategy.
- What is Hadoop technique and what are its advantages in context of Big Data?
In the thesis, Hadoop technique will be focused because of its advantages to provide ability for scaling and managing the large volume of data.
- What are the advantages that big data environment provides to the system?
While answering the questions, advantages of big data environment will be focused along with its features in the context of this thesis.
- Through what process the relevant information will be collected?
The processes that are required to collect the relevant information can be find while answering this question. There are various data resources will also be elaborated.
- What processes are required to eliminate the challenges associated with the Big Data environment?
The processes will be considered in the question that are required to eliminate the challenges in the big data environment, existing.
- What is the need of security in Big Data?
While answering this question the need of security in the big data environment will be provided and also the points will be evaluated that are comes under the big data environment.
Chapter 2
Background
The generation and collection of data are quickly increased in the technology world. The data has also increased with the high in the last few years. The Big Data has introduced some challenges for businesses and organizations. Though, the Big Data is a database that is hard to keep, communicate, capture and analyze, using current and traditional technologies. Apart from these security and other challenges, Big Data provides the ability to generate revenue, overall efficiency, quality of services and developing products. With the complications of analyzing and evaluating such a high volume of data, traditional privacy and security mechanisms are ineffective when the analysis is required (Yi Li & Li 2015).
2.1 Explanation -of Big Data –
Big Data technology is having a large volume of data stored into it. The data is major of two types, structure and formless data. Therefore, it is not easy to make the flow of such large data using traditional software and systems. Generally, the Big Data effectively explained into four different terms. The four terms are represented into following sections –
- Volume – the size of data is denoted as the volume of Big Data. It includes storing of data, the transaction of data, real-time streaming of data and collection of data from the various sensors and IoT based devices.
- Velocity – the velocity has represented the speed in which the data are flowing in the system. It also defined as, on what level the data is producing and processed to accomplish the demands.
- Variety – the data comes in various formats. e., text, traditional, audio, video, existing databases etcetera.
- Veracity – veracity in the Big Data environment described as the consistency as well as the reliability of the data (Yin & Kaynak 2015).
There are various important data collected from the several resources such as, credit card transaction data that comes across the world, large e-commerce site’s customer transaction and the interaction data that generated from the social media users. Terms such as map-reduce and Hadoop cannot be evaded while attempting to understand the security concern of the Big Data environment (Jiang & Meng 2017).
2.2 Hadoop
It is a software that has developed and used while processing large scale of data. It also enabled the data to process across the clusters of computers through the programming models. The concept behind the development of Hadoop is that it enabled the scalability of data from the solitary server to the numerous servers. Where each server provides local and computational storage. Servers are key in the Big Data as without the server appearance; data cannot be transmitted and proceed. The data is the input of the Hadoop framework as the Big Data is all about the data feeding. It has already been discussed that the data originated and came from the different-different sources and in the different formats. The Hadoop system has its system on which it works, named as HDFS. The HDFS system helps to store the data numerous servers and different functions. One of the examples is NameNode. NameNode helps to store DataNodes or metadata, application data stored by the NameNode (Chatfield Reddick & Al-Zubaidi 2015).
The Hadoop system works on the programming that based on the Java. It further helps in the process the high volume of datasets, as it also known as the distributed computing environment. HDFS helps in the rapid transfer rate of data and remain the system in working continuously even when some nodes got failed. Therefore, this system reduces the chances of entire system failure. The Hadoop system is very reliable and effective when it comes to transferring a huge amount of data. Hence, companies like, Google, Amazon, and Yahoo etcetera, using Hadoop framework to manage their application with a large amount of data effectively. Hadoop has its main two subjects – Map reduce and HDFS (HDFS).
2.3 Need of security in Big Data
There is a number of businesses and organization are relied on the Big Data technology to secure and store their high volume of data, but sometimes they do not have the important and fundamental resources from a security perception. If in case the loophole occurred in the security of Big Data, it could cause serious legal consequences and could also harm the reputation of the respective organization or company. In the current scenario, several numbers of organization are with the Big Data technology to store and analyze their petabytes dataset that related to the company, organization or their customers. Due to the high volume of data, the classification of information became more tough and critical. In the way to make Big Data more secure and private, several techniques are available to adopt and gain. The techniques are named as, logging, encryption, honeypot detection, and many more are necessary for keeping the confidentiality of the dataset. Some organizations and companies are successfully deploying the Big Data technology for fraud detection (Vatsalan et al. 2017).
The issues of preventing and detecting advance threat agents and malicious attackers, Big Data-style evaluation should be placed to solve the issues of detection. These types of techniques help in preserving the security threats and in the early stage of data damage. For making it more effective and accurate more sophisticated and feasible pattern analysis can be adopted. Security and data privacy are the issues that are causing security threats to the federal organizations and industries. As the dependency on the Big Data is increasing day by day, therefore, the businesses are not only suffering from the data security but also from the privacy issues. In the way to maintain the confidentiality of business-critical data, balancing of national security and data privacy should be maintained.
Existing systems are insufficient to maintain Big Data security and privacy. Nowadays, threat agents are targeting control access, encryption protocols, transport layer, and firewalls. Therefore, the more advanced and effective privacy and security systems are settled in the way to monitor, audit and protect Big Data environment and its processes (Matturdi et al. 2014). The security of Big Data can be categorized in the following way –
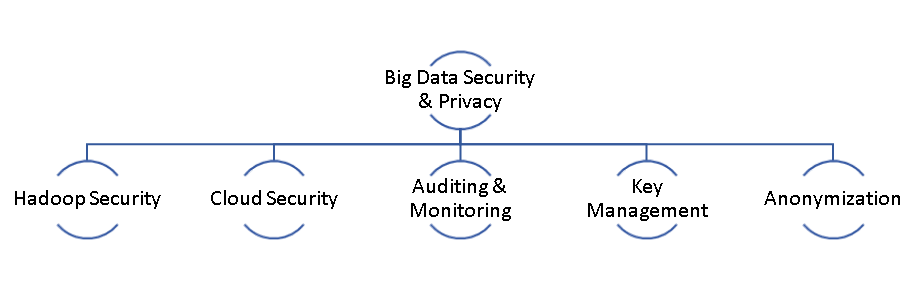
Figure 1: Big Data security and privacy categorization
(Source: Author, 2018)
Hadoop security – The Hadoop system has developed for the distribution of data but not developed for the security purpose. The reason behind the settlement of Hadoop was to operate in a trustworthy environment. It has become a popular platform for data processing. Towards that, security protections are also under development. In the way to develop security system which is reliable and accurate, multiple techniques were introduced to eliminate the hackers that are targeting on the entire data that has stored in the cloud. Therefore, reliable techniques HDFS (HDFS) has implemented along with data nodes. As per the principle of HDFS, user or customer need to provide authentication of himself to get the access of name node (Hota Upadhyaya & Al-Karaki 2015).
The user authentication process works on the several steps – Initially, hash function sent by the user and further the name node also produced a hash function. Both the generated functions are compared in the next step. After the comparison, if the result is accurate, then the access is provided to the user else rejected. To make the authentication more accurate and precise, an SHA-256 hashing technique is used. Also, RSA, RC6, and AES (types of Random encryption techniques) have also been used to prevent hackers from getting access to whole stored data. Towards making the encryption process strong and secure, MapReduce technique has also used that performed encryption and decryption process. Finally, both the methods are examined using twitter stream approach for demonstrating the way to preserve safety and privacy challenges (Lee Kao & Yang 2014).
One more unit is there that causes the privacy and security weakness, named as HDFS. In the way to increase the security of HDFS three methods are proposed. The first method, the Kerberos mechanism has proposed to address the security issue. This technique based on the ticket granting service. Secondly, Bull Eye algorithm has introduced that provided the ability to auditing all sensitive and critical information in the view of 360˚. The mechanism has ty implemented to ensure the data security and maintain the relations in replicated data and original data. Hence, only authorized and identified users could get access to sensitive and private data (Gupta Agrawal & Yamaguchi 2016).
Finally, two name nodes have been introduced to knob the name node problems. These are categorized into master and slave, respectively. If in case, any cause occurred to the head node then the administrator gives the critical data from the slave name node. The data given procedure based on the permission of Name Node Security Enhance (NNSE). Consequently, data availability and latency issues are succeeded in a secure way (Najafabadi et al. 2015).
Cloud security –
In the cloud environment, data management and security are one of the major issues. Hence, some of the precautions are needed to be occupied by the service providers. Therefore, a secure and reliable way has been proposed to handle the Big Data management at the cloud platform. There is a number of security protocols, named as decryption, encryption, authentication and compression, all for securing the stored Big Data. For the authorized users, email and password-based authentication have been used. This has been introduced to encrypt the data to avoid security concerns. Also, three backup servers are used to avoid the loss of data while natural tragedy. The data has been stored in an encrypted format, at these servers. Also, if anything occurs on the server, encoded and secured data has been decoded using the secret key (Wolfert et al. 2017).
The traditional encryption techniques are not reliable for the Big Data integrity of the cloud. Therefore, the advance scheme has been proposed to safe the Big Data. The projected technique named as identity-based authentication algorithm and key establishment scheme. As per the proposed system, all the data has been detached to different-different parts, and all the parts are stored and located in diverse storage providers. Securely, only that data has been encrypted that having critical and important information rather than the information which are useless and computational. The proposed scheme also made the copies of all the data types or parts. Therefore, if the data get lost due to some reason, then the information available will be maintained successfully (Jain Nandakumar & Ross 2016).
Monitoring and Auditing –
The process of auditing and monitoring is done in the way to catch the interruptions in the system. Detection and prevention of interruption are rather difficult in network traffic. To address the issues of security monitoring, a security auditing architecture has been proposed using analyzing IP flow records, honeypot data, DNS traffic, and HTTP traffic. The introduced scheme also included processing and storing data using data relationship schemes. In the next step, identification of domain name and flow is made to identify that the process is malicious or not. After the analysis process, the score got finalized. An alert generated to in the detection system to avoid the security issues or it is terminated by the prevention system. The network security system in the Big Data needs to be identified faster and quickly so that the alerts could be generated from the mixed data. Hence, the feasible and reliable monitoring system has proposed for the security of Big Data. The proposed solution has included several modules – Data integration, data analysis, data interpretation, and data collection. These modules are described as follows –
Data collection, it consists of network device logs security and all the information of events. Where the data integration stage is achieved by data classification and data filtering. Further, in the process of data analysis, association and correlation rules are achieved to catch the events. In the process of data interpretation, statistical and visual outputs are provided to knowledge datasets that predict the behavior of the network, event responds and helps to make decisions (Gai et al. 2016).
Synchronization of the suspicious and non-suspicion data in the monitoring of Big Data is also an issue. In the way to make the process more accurate and efficient, the self-assuring system has produced that includes four different modules that help to identify the abnormal user behavior. In the first module, includes keywords which are related to the doubtful behavior of user that is called the library. The second module named as the low critical logs that helps to records the identification and authentication information to figure out the suspicious behavior. In the third module, high critical logs are presented, that helps to identify that the low critical logs are reaching the threshold value or not. Finally, the self-assuring system has introduced that is having the ability to evaluate whether the user has detected as suspicious or not. If yes, then the user is prohibited by the system (Chen et al. 2014).
With the increase in dependency on the Big Data, some of the issues have also occurred in other words, the consistency of data, data availability, data identification, data integrity and integrity of data. Therefore, some advance and secure authentication and precautions are required to fill the gaps in the Big Data environment. One of the precautions found is replica nodes. It can provide data availability with user satisfaction. It has the feature that the important information will be available even when the data lost due to circumstances. Through the replica nodes, data accessing is quite fast and easy. But, replica nodes are also vulnerable to security threats. It causes trouble in data integrity. Though, authentication issues, user auditing, and communication overhead have been eliminated using proposed Multi-Replica Merkle Hash Tree (De Greco & Grimaldi 2015).
Key Management –
The implementation of key-based authentication has done to enhance the safety and privacy of the data access process, but it has raised security issues in the Big Data when the key sharing and generating between the users and servers. Dynamic and quick authentication systems can be recommended. Also, PairHand protocol and Quantum protocol has been proposed. The proposed Quantum techniques provided low complex and strong key generation, and PairHand provides authentication to the fixed data center and mobile devices (Solanas et al. 2014). The proposed model has several levels, front end, reading the data, quantum key processing, key management, and layers of the application. The proposed solution has provided effective key search operation and reduce the chances of passive attacks and slightly increase the overall efficiency.
There are a variety of formats are available in the Big Data environment such as texts, XML, emails, and multimedia. These data are difficult than the unstructured data. The proposed method has multiple stages to secure the data. Fist stage is analytics of the data and security suites. In the phase of data analytics, clustering, data sensitivity, and filtering process have completed. In the next phase, security services such as authentication, confidentiality, integrity, and identification have done in the security suite phase (Akter & Wamba 2016).
Anonymisation
The Big Data privacy issues come from the data harvesting process. Due to the quick sharing of data in the Personally Identifiable Information (PII), it is quite hard to protect such information. Therefore, to eliminate the security concerns from the system, an agreement should be signed between the organization and the individual to maintain the data confidentiality through the policies. The critical and personal data that is less secure need to de-identified and forward to the secure channels for reducing the chances of attacks. The proposed solution also provides predictions, but these predictions lead the system to the unethical issues. In the personally identifiable information has eliminated from the Intel circuit, where the portal usage logs are given to maintaining the data integrity. The proposed solution produces anonymization. Sensitive fields in the data logs are anonymized by the AES key encryption and further store the log data in the HDFS for the evaluation and analysis process. Further, the anonymization quality is calculated using k-anonymity that is based on the metrics.
2.4 Infrastructure Security
While deliberating about the security infrastructure, it is important to know to about the key frameworks and technologies found as the perspective of security the Big Data architecture. Majority of the technologies are based on the Hadoop because it has used very frequently. In the section data availability and Big Data, communication security is also discussed (Abbasi, Sarker & Chiang 2016).
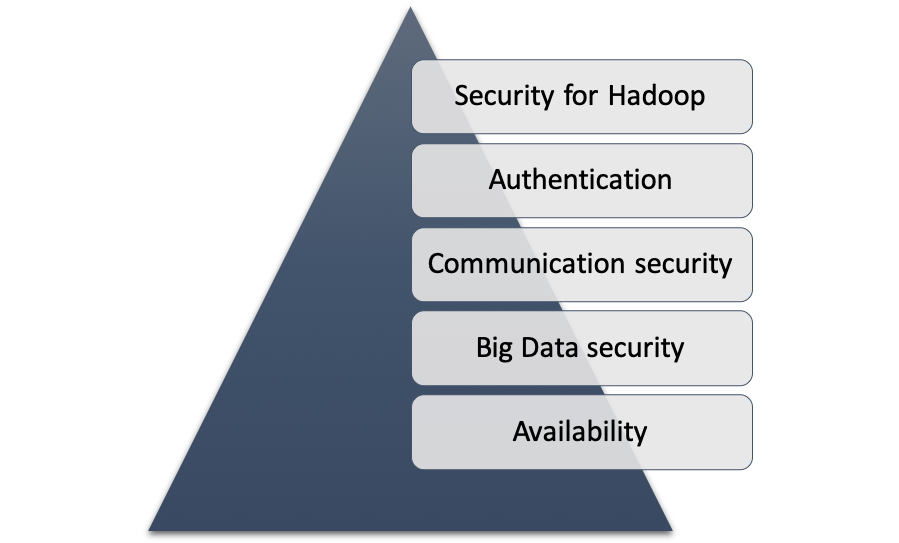
Figure 2: Infrastructure of security in Big Data
(Source: Author, 2018)
Security of Hadoop –
Previously, Hadoop security has been discussed already. Also, the Hadoop in the bog data can be measured as the de facto standard. This standard can be used for implementing the Big Data environment in the company of the organization. To overcome the security issues, some frameworks have been proposed by the researchers that assist to maintain the security of the Hadoop system.
Availability –
The availability in the Big Data environment is defined as the requirement of the data and flow of the data which has come from the number of computers that not only having data stored in it but also replicated with the clusters. Hence, the system that is having the feature of providing data availability is required on the priority basis (Inukollu Arsi & Ravuri 2014).
Architecture security –
In the way to increase the security of Big Data, more feasible and reliable architecture should be composed or need to be updated. Therefore, network coding and multi-nod reading can be implemented to eliminate the security problems in the Big Data.
Authentication –
The Big Data is having a high volume of data gathered from several devices across the world. Therefore, security and authenticity are required to eliminate the chances of security threats.
2.5 Big Data security measures
Some security portions need to occupy toward increasing the security of Big Data environment; these are as followed –
2.5.1 File Encryption
As all the data gathered in the Big Data, further stored in the machines and hackers can easily hack the user’s personal and critical information (Zhang et al. 2017). Therefore, the data should be encrypted and authenticated to enhance the security of the data. The data need to secure in the strong encryption keys, and all the keys should be placed at the private and secure place or firewalls. Hence, if the hacked seek to hack the data, they cannot get all the critical and useful information. The meaningful information of users will be secured in an encrypted manner.
2.5.2 Network Encryption
As the Big Data environment, communicate the data on the network system. Therefore, all the network communication must be encoded in the industry standards (Sharma & Navdeti 2014).
2.5.3 Logging
All the networks and map reduce jobs that are having rights to modify the data, must be logged and the respective user’s information should be logged to reduce the chances of security threats. After logging the useful information, it needs to be audited on a regular basis to prevent the malicious attacks and restrict the malicious attackers.
2.5.4 Node maintenance and software format
The viruses are entered into the system only when the software is outdated, or nodes are not maintained regularly. Therefore, Hadoop software and various application software must be updated to increase the security of the system (Patil & Seshadri 2014).
2.5.5 Authentication of Nodes
The process of joining nodes and the cluster must be authenticated. It would help to restrict the malicious nodes before joining to the cluster. Kerberos etc. can be used as an authentication technique to authenticate the nodes.
2.5.6 Rigorous System Testing
The map reduces jobs must be tested thoroughly in the distributed environment rather than the single machine. It helps to maintain the stability and robustness of the map reduce job.
2.5.7 Honeypot Nodes
As the nodes are important in the Big Data environment to join the cluster, therefore, honeypot nodes should be placed in the system. Although, the honeypot nodes are appeared as regular nodes but stand a trap. It helps to trap the hackers and eliminate them for securing the data from the hackers (Riggins & Wamba 2015).
2.6 Big data privacy and security and challenges
- Making the calculations secure in a Distributed Programming Framework: In this basis, there is parallelism that takes place in computation and also in place of storage for the processing of large data. For example Map-reduce framework, in this the original file is reduced into multiple chunks after that using mapper the data for every chunk is read and computation is done on them and at the output, the key pairs are seen. And in the next step, the values of the distant key is combined and outputs the result. In this, the attacks are prevented by securing the data and mappers when the untrusted mappers are present.
- Securing stored data and transactions: the transaction logs and the data stored is made secured by giving the manager a direct control to check when and where the data moves. The size of the data is growing exponentially which increases the necessity of proper big data storage and management. To track the data and the changes made is a challenge that is faced in securing the stored data (Tsai et al. 2015).
- Security issue in Real-time / continuous monitoring: when the monitoring is done in real-time it is kind of security is a challenge and the alerts are made by the device. The false alerts may route to the various false results that are majorly ignored. This the problem is increased with the increasing big data in the volume and velocity and for this big data, technologies are given an opportunity for processing fastly and analytics of various different kind of data.
- Filtering/ end point input validation: the big data is collected from many sources, for example, securing the stored information and managing the events in the system collects the event logs from various software models and from hardware’s devices also. The major challenge is that how the collected input data can be trusted and how to filter that input data from malicious attacks? This input validation and filtering these data so that they are not taken from any untrusted input sources (Kitchin 2014).
- Secure communications and Cryptographically Enforced Access Control: for securing data to the end users so that data is only accessible to the authorized users the data is encrypted using access control policies. Attribute-based encryption is used as it makes data secure, scalable, more rich and efficient. For making data authentic and distribute it with different entities a secured connection using Cryptography framework is implemented (Sun et al. 2016).
Chapter 3
Literature Review
In chapter 3 reviews on several security challenges in the Big Data and existing and traditional security systems for maintaining the confidentiality of Big Data. Section 3.1 describes the method of Saraladevi et al. (2015).
3.1 Kerberos, Algorithm and Name node Approach on a domain environment
The authors proposed a solution to enhance the integrity of the Big Data environment. In the paper, Saraladevi et al. has focused on security issues associated with the Big Data environment and further, aimed at the security issues of HDFS. The security of HDFS increased through the three effective and reliable approaches, named as Kerberos, NameNode, and Algorithm.
3.1.1 Problem Statement
In the current technology world, Big Data is growing and will rule the world shortly. Various data are flowing on the networks and internet, including marketing and technical data. The data that collected on the large-scale termed as Big Data, and due to high volume, Big Data is always vulnerable to the security challenges. Big Data is quickly getting large. Reportedly, Big Data reached from GBs in the year 2005 to Exabytes in the year 2006. As online, the Big Data is storing terabytes of data, thus, cannot be stored and maintained by the existing and traditional systems.
Apparently, some difference occurs in the traditional data and Big Data. Table 1 provides the comparison –
Table 1: Difference between traditional data and Big Data
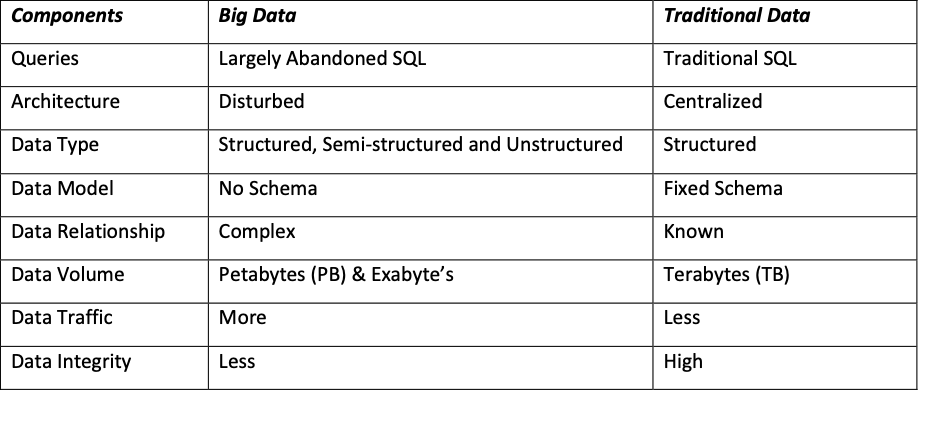
By the high quantity of data in big data, management and communication of data in a secure manner is a challenge. When the high volume of data stored at the database which is less secured and not encrypted. Often, hackers are targeting the database that is public. Further, the hackers copy the public data and store it into their devices such as hard drives, laptops etcetera. After getting the access of data or the copy of data, hackers attack the system. Attacks such as denial of service, Spoofing, and brute force etcetera. Therefore, if the volume of data increased from tier to tier, the security level should also increase respectively. Towards that, some robust and sophisticated techniques to secure the insecure data should be implemented in big data environment. Currently, several tools and techniques are developed to reduce the chances of security threats shortly. Such as Hadoop, NoSQL. The research focused on the elimination of security issues in traditional Hadoop system (Yi Li & Li 2015).
3.1.2 Hadoop Environment

Figure 3: Architecture of Hadoop
(Source: Saraladevi et al. 2015)
HDFS is a file system that based on the Java. It is highly reliable and scalable as well and spread over the Hadoop framework environment. The feature of the framework is that it provides commodity hardware that provides terminated storage of a high volume of data with less latency. Operations such as “Write once, read many times.” Performed using the system and here the data stored in the block terms with the standard size of 64 mega bites (MBs). Remote procedure calls are used as a communication tool that provides communication between the nodes. In the Name Nodes, several metadata stored such as replicas, attribute files, name, and block locations etcetera. All these data are stored in the RAM (Random Access Memory) by Metadata.
Security issues in the HDFS
The HDFS is the concept layer of Hadoop environment. It is less secured; thus, it is always vulnerable to security threats. Generally, government sectors are not securing their valuable data into the Hadoop environment due to its low level of security. The HDFS has prohibited with the security for evading vulnerabilities, thefts, and security issues by encrypting the block levels.
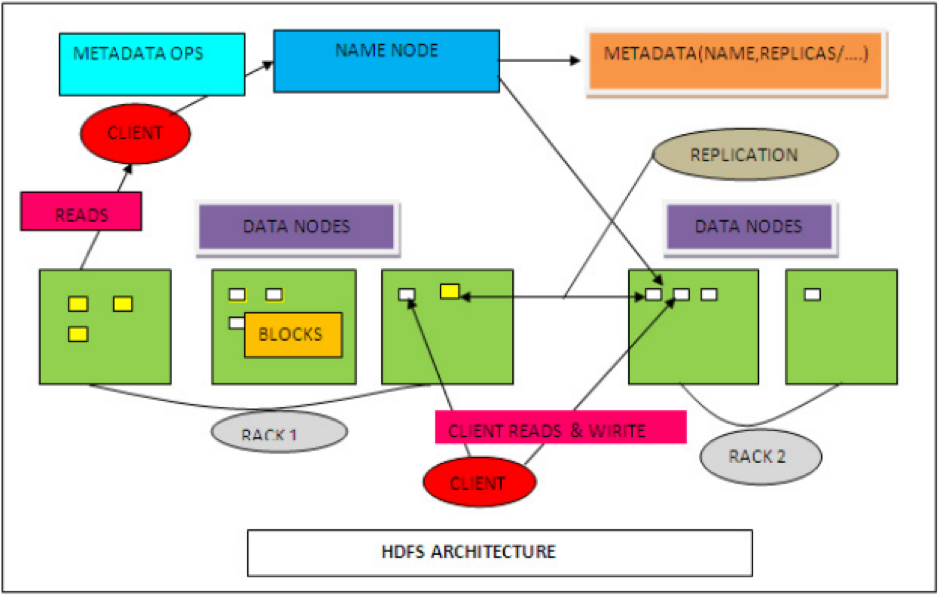
Figure 4: HDFC Architecture
(Source: Saraladevi et al. 2015)
There are several approached for increasing the security of data in the HDFS (HDFS). Some of them are as followed –
Kerberos Mechanism
There are several security issues while transferring the data or file in the Big Data environment, towards reducing the chances of security issues, Kerberos has introduced in the research. Kerberos is an authentication procedure that enabled the node to allocation or communicates file even on the non-secure network. The process of transferring the file over the non-secure data, a tool named ticket. The ticker provides unique identification between the files that slightly increased the security of the data (Stojmenovic et al. 2016). Therefore, the proposed Kerberos mechanism is used to increase the security and privacy in the HDFS. Using Remote Process Call provided linking between the Name node and client and by using Block Transfer, the connection between HTTP clients to Name node is accomplished. Further, the Kerberos used as the tool that provides authentication of RPC connection. Both the Ticket Granting Ticket (TGT) and the service ticket is known to authentication Name node through the Kerberos mechanism.
The proposed Kerberos mechanism is consisting of several stages to provide authentication to the HDFS process. In figure 5, initially, if the client or user wants to retrieve the block from the data node, they need to contact the node on the way to recognize the node of data that stored files. Only the authorized users get the permission to access the file and to increase the security of the file, a block token generated.
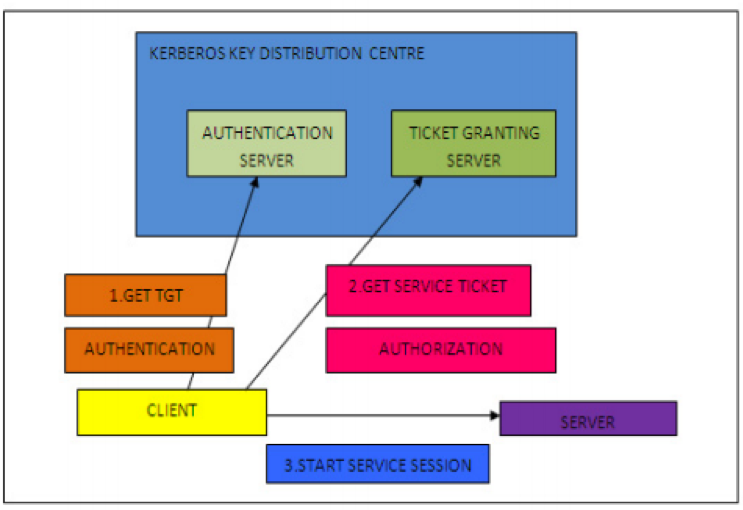
Figure 5: Kerberos Key Distribution Centre
(Source: Saraladevi et al. 2015)
The Name tokens and Block tokens are forwarded to the clients who are having a data block, individual location and containing information the being is authorized to access the location. The Kerberos Mechanism used to enhance security by avoiding unauthorized clients. Figure 2 presenting the Kerberos key distribution that assists to enhance the integrity of the HDFS (Cui Yu & Yan 2016).
Bull Eye Algorithm
There are several important, and critical information (such as important passwords, card, credit, debit and personal details, account number etcetera) are stored in the Big Data or the Hadoop technology. Therefore, the Hadoop technology required sophisticated and feasible security protocol that can increase the security of sensitive information stored in the Hadoop. Towards that, bull eye approach is proposed in the research which helps to see all the critical stored information in the 360˚ that helps to check the security of the information. The proposed bull eye algorithm also allows the users to secure their sensitive information in the right and secure way. The bull eye algorithm has been used in the companies named as Amazon Elastic Map Reduce and Date guise’s dog secure. The companies are providing security to the governance solution and data-centric security and also helps to increase the integrity of Hadoop in the cloud environment. The company has successfully maintained the data confidentiality but in the current scenario, when the company started securing more sensitive data into the system. Therefore, the company required security approaches such as bull eye algorithm because the existing and traditional security system are started breaching the data. The approach is feasible and secure as it is regularly checking the security of data stored in the Hadoop technology and also checking that the security of Hadoop stored information. The implementation of Bull Eye Algorithm increased the security of data as it regularly checks that the data is stored properly in the block or not and the algorithm only allows the limited customer to stock in the compulsory blocks (Manogaran et al. 2018).
The proposed bull eye algorithm goes from TB to PB of structured, semi-structured and free data kept in the HDFS layer in every angle. At the block level, wrapping and encryption of data occurred instead of at the entire file level. The bull eye algorithm scans the data before entering in the clouds and further check where to enter in rack1 and rack 2. Consequently, the bull eye algorithm used to secure the sensitive information stored in the data nodes. The bull algorithm has been proposed, in this paper, to increase the security of data nodes of the HDFS (Sarladevi et al. 2015).
3.2 Kerberos, Algorithm and Name node Approach on a domain environment
Stergios et al. 2018, proposed base technology cloud computing to function in the world of Big Data. The Big Data technology’s base is cloud-based databased and cloud computing. In the research, the addition of IoT and CC has observed that in the Big Data, privacy and integrity of useful and critical information is a problem that needs to be focused. Therefore, some motivations are assumed in the research. When the sensitive Internet of things applications are move from ward to the Big Data technology, security issues are arising due to the absence of trust on the service providers and the information about the SLAs and the information about the position of data. Due to the multi-tenancy, the security concerns arise and caused leakage of sensitive information. Also, public key cryptography is not applicable at all the layers because it further increases the consumption of energy or power at the cloud data centers.
Towards, the enhancement of the security as the Big Data environment the study new system is proposed. In the wat to eliminate the security challenges in the Big Data, technology, architecture has been established that is based on the security of the server.
In figure 6, towards enhancing the security of the cloud servers, a security wall is placed between the users and cloud server. To overcome security and privacy issues. The proposed system using all the existing topologies, i.e. ring, star etcetera to provide good communication and safe transfer of Big Data by the network.
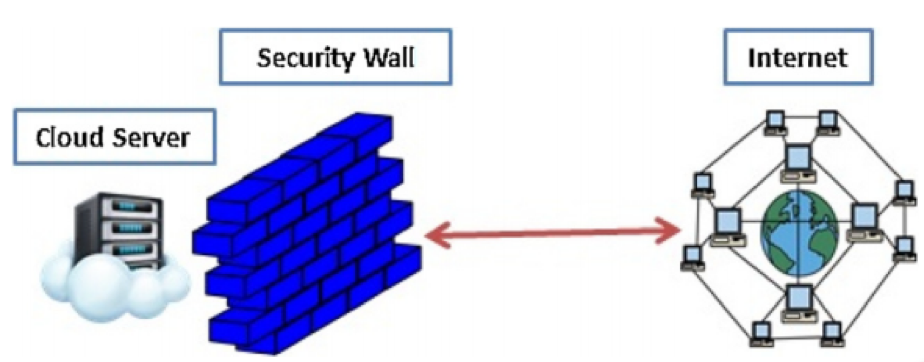
Figure 6: Network scenario based on the strong security wall
(Source: Stergiou et al. 2018)
Implementation of the proposed model, scalable and innovative service platform can be developed to provide privacy and security services. By the proposed solution, some of the parts of algorithms are introduced that can help to extend the security of Big Data technology. As per the proposed solution, 128 bits/16 bytes original key has used, and it is represented in 8 X 8 matrix –

The proposed solution introduces secure paths between the server and the user. The connection is depending on wireless communication. As shown in figure 7, the network (server) and internet connection done by the wireless router and at this place the key feature of the solution, “security wall” is installed.
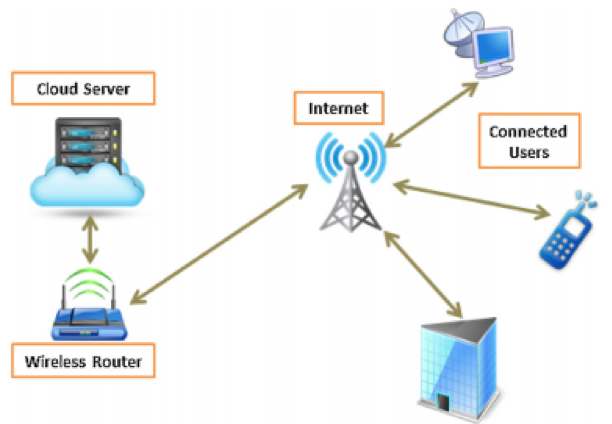
Figure 7: Wide-range network of cloud computing
(Source: Stergiou et al. 2018)
Therefore, if the user is identified and authorized through the security protocol, then they can get the access of their data through the internet. Also, they can communicate and manage transferred data.
The proposed cloud computing solutions have provided various benefits to the individuals as well as small and medium enterprises. The Big Data security has been increased after implementing the proposed solution. Following are advantages of the cloud computing technique –
- The applications are cloud-based that slightly reduce the need for expensive computing systems and reduce the overall cost.
- Provide access through the Internet-based system but only authorized and identified users can get retrieval to the critical data.
- The proposed solution is sponsored by the state-of-the-art security solutions that increased the initiative data safety.
3.3 Security issues and challenges of Big Data analytics and visualization
3.3.1 Challenges related to security
The Big Data environment is used in resolving many of the cybersecurity issues, and also it finds the attackers. There many security challenges that are faced in Big Data and also these security issues must be analyzed. The major challenges security challenges are:
Fraud Detection: a large data is created and not only are this major event created by many large enterprises. From different sources the events are created, more enterprises are deployed, more employees are hired, and more software is used for post hoc forensic analysis. For a result, proper analysis and prediction of data are done (Kim et al. 2014). In fraud detection, it is suggested that Big Data analytics must be used. Companies like a bank, credit cards, etc. is majorly affected by fraud detection. Major technologies of Big Data are Hive, RHadoop, Pig, etc. and also there are many analysis tools which work which are applied to large datasets. These technologies are used in facilitating storage, security information, maintenance, etc.
Data Privacy Issues
The data privacy depends upon the organization, and on the ways, the organization uses the data. The data is collected from various locations, but these are not shared with anyone. In the market, many tools and techniques violate the data and extract the personal data of users. So for removing these security policies needed to be applied in the process. Various approaches are needed to be introduced for protecting the sensitive information (Diamantoulakis et al. 2015).
Network Forensics
In the Network Forensics system, the traffic in the network is monitored continuously for observing the unusual behavior or abnormal pattern in the normal traffic by which the attacks are identified in the network. Using Network Forensics investigation of traffic associated with the networking is done, and the large data volume is analyzed in the environment. There occurs major challenges with the problems are accessing the network devices, and these challenges are resolved using Big Data analytics. Bayesian classification is a technique of data mining classification used for predicting the attacks in the networks.
Data Provenance
Data Provenance means that the origin or start of data from where it was generated when it was generated and the location of the data. This problem is arising as collected data from various sources faces trust issues. With this trustworthiness, related problems are caused. Using data analysis tools authentication and trustworthiness of the data need to be analyzed. Also, statically algorithms and some of the machine learning algorithms are executed for analyzing the malicious data. But the data Provenance issue has also had an advantage e that using it helps in keeping track of data location and origin. Visualization techniques are used in identifying the problems caused due to data provenance (La Torre Dumay & Rea 2018).
3.3.2 Security Issues of Big Data
An everyday number of data is generated near zettabytes. And it is increasing every day, and this data is viewed in four dimensions; velocity, Veracity, volume, and variety. In analytics, the large volume of data is processed using mining algorithms, and for this purpose end, performance computing devices are also used. The time taken for this is very less, but the major issue with Big Data is the security concern. Security issues faced in the Big Data majorly includes the data provenance, access control, analyzing data in real time and making transactions in a secured manner.
Using Big Data Analytics for the Security
Both encryption and the data decryption are done as a part of proper analyzing. Major encryption algorithms are Rijndael 3DES, Blowfish, etc (De Greco & Grimaldi 2016). The data is explored, and knowledge about them is gathered using data mining techniques. One of the major tool used is Hadoop for data processing and increasing the security in the system. A large number of data are no examined using traditional security mechanism. In Big Data, the information is collected from various sources in the real-time and with using the tools of Big Data the huge data is analyzed in a short period. Big Data mining helps in making a decision and also helps business in increasing opportunities in the future (deci
Visual Analytics
Visualization is used for representing the data, and this helps the humans in inspecting all the data with the help of graphs, pie charts, images, and many other kinds of data. Visual Analytics has many challenges as in this it is not concerned only with the representations, but it also provides tools for analyzing the data. In today’s world, Dynamic data visualization is becoming popular day by day, and many software is used by Big Data visualization for processing. In Visual Analytics the visualization techniques and Big Data analytics both are integrated, and this helps in data visualization and also it supports different views of representation. The major challenge with this is that the representation of data is difficult in Big Data. This helps in fraud detection in many applications like weather monitoring, forensic analysis, credit card, and network analysis.
3.3.3 Bayesian Classification Mining
Forensic profiling is a method that is used for developing the information and it also with the help of data mining evidence is derived. From a different data source, a forensic profiling pattern is derived. The Supervisory Control and Data Acquisition are used for extracting the historical data by integrating network forensics and data mining. A Naïve Bayesian Classifier is proposed which is used in predicting the network flow under the network attacks. In the SCADA system, major algorithms used are regression method, decision tree, etc. Naïve Bayesian classification is an algorithm predicts the class label. The main assumption in Naïve Bayesian classification is made that all the attributes in it are independent of each other and this assumption is known are as class conditional independence. Making this assumption the results are retrieved fatly in an effective manner.
3.4 Big Data technology in the education sector: Openings and contests
In the institutes of higher education, various operation are there which are complex in the environment. These institutions are under high pressure of many changes like political changes, social changes, and global, national and economic changes. Also, it is pressured for giving quality work. In this part of the research, big data technology is given in the modern issues faced by higher education. In this paper, the factors that affect higher education are identified, and also it explores the Big Data potential and analytics that helps in addressing these changes. In the challenges, opportunities that associated Big Data in higher education are also explained (Huo et al. 2017).
3.4.1 Data mining methods Information detection
Knowledge discovery is an area in which methods are given that is used in identifying useful information and the patterns that are meaningful, and this information is also extracted from the large datasets. The research is done on databases, machine learning, optimization, info, pattern identification, visualization of data, and computing with the level of performance.
Data mining
With using Data mining; analysis is done by which pattern is recognized from the data and is a major aspect of KDD. But in the past many years, data mining is replaced by clustering, regression models, classification algorithms, factor analysis, predictive methods, and association approaches.
Data segmentation
Data segmentation or clustering is an approach in which the data items are grouped by logical relationships. The main goal is to group maximize the intercluster similarity and also minimize the intracluster similarity. In feature selection, the features that are used most commonly are combined for clustering.
Classification
A classification is an approach in which data mining is done classifying the data into categories that are defined. In this approach, the machine learning algorithms are used. In this algorithms, data is taken from large pre-defined data sets. They are used for determining the differences and further classifying the data according to the groups.
Association
A new approach is an association approach in which according to the characteristics the data is grouped and the characteristic of data is extracted. This is an algorithm based on rules which are used in examining the relationships among the sets of data. Using this the frequency associated with the items are examined, and the relationship between the items and data is studied. Using a simple association rule the relationship is given between two different items (John Walker 2014).
Regression
Regression is a common data mining approach using which the predictive models are constructed. There is a lined reversion which is equal to the linear replicas used for testing the implication of the static data.
These predictive models are used in educational data mining for referring data aspect and also in this different aspect of data are combined together. In the education sector factor analysis is also done for finding the variables and grouping them or with this, the variables are split into the different latent factors. The major types of analysis algorithms are exponential‐family principal components analysis, principal constituent analysis etc. used to minimize the dimensions. It also has the potential to determine the meta-data and performance overfitting. For developing predictive models, factor analysis is done (Lazer et al. 2014).
These above data mining approaches are applied in the educational sector for data mining research. In these various approaches, it includes machine learning, the area of stats, psychometrics, data mining and other areas such as information visualization, computational modeling etc. All the traditional methods and these approaches mainly aim at making a process automated for detecting the interpretable pattern and with this the predictions done. This educational data mining mainly focuses on the development of tools that are used in discovering patterns in the data and these tools and techniques are applied to analyzing large data sets.
3.4.2 Emergence of Big Data
Today there are various organizations that are using data for making the data and decisions better related to the operational and strategic directions. From last many past years, data is used for making decisions; many large organizations are storing the large volume of data and analyzing that data from warehouse since 1990s.the data stored in the organization is changing its nature and with these changes, the complexity for managing and analyzing such large volume of data is increased. Today most of the business runs on the structured data i.e. on the categories and on the numbers. With this, the complexity of the corporate data and the hidden business values are not reflected. It is observed that according to IBM today 80% of the data organizations are generating data in unstructured formats such as images, text, diagrams, video, audio and combining more than two or more formats together (Chen & Zhang 2014).
Today maximum of the data is stored in the warehouse of the corporate sector in an unstructured manner. Data warehouse means that it is a place where all the database is stored and it is a kind of a central repository where all the database is placed. It has a large memory where data is stored and where anyone wants to use it can be collected from here and used for making decisions better. With new technologies introduced in the market, it is becoming easy for collecting the data and also maintaining a large amount of complex data and these data are collected from various sources (Kim Trimi & Chung 2014).
In big data, there is a too big data and also it moves fastly which is very much improved in comparison to the properties of conventional database and types of a traditional system used (Manyika et al, 2011). In also include various new technologies and techniques to collect the data and also to store it, send it to various locations and to manage the distributed data from various locations. It is used in properly analyzing large size big data and all the structured and unstructured data.
3.5 Security Issues and Challenges in Big Data Analysis
Big Data is a collection of massive data sets that have large data which has a complex structure, but these large data is having difficulty analyzing, visualizing and storing for obtaining results. This searching of patterns and the correlation is defined as data analytics. With the growing data, challenges are also increasing for data storage and its privacy (Assunção et al. 2015).
3.5.1 Stages involved in Big Data
The major stages involved in the big data are as follows:
- Data Acquisition: This is a first step in which the data is acquired itself by the big data. Day by day the rate of data is increasing exponentially, and the new devices are introducing which are using it. Among all this available data there are data which is not useful so that data is needed to be discarded. For providing large data storage to the available data, the cloud is used.
- Data Extraction: the data that is generated and acquired is not used as in this there is data that is redundant and also not necessary. The major challenge is that to determine the data that is to be discarded and also to build a common platform for standardizing of data as no common platform is available for storing data.
- Data Collation: the data is not collected only from a single source, but it is combined from various sources. For example in health monitoring system data is collected from various sources and devices like a pedometer, heart rate sensor etc. Similarly, for examining the weather conditions, various data is collected such as humidity, precipitation, temperature etc. This data collection is an important part of data processing (Lv et al. 2015).
- Data Structuring: after collecting all the data the next important step is to store the data and store it in a structured form. With the proposed structure queries are made on the data and by this, the data is structured in a proper schema. With NoSQL, the data is in unstructured form, so the issues are created and the results are not provided in a real-time and aggregation is also not done.
- Data Visualization: After the data is structured and the query is made that data is presented in a visual format. With analysis, the major areas are targeted and results are on the basis of structuring. The analysis and presentation make the consumption of data easy for the users. Raw data itself I, not enough so proper visualization is needed.
- Data Interpretation: this a main step as in the values that are taken as input are processed.
This obtained information can be of two types:
- Retrospective Analysis: in this, the information is related to the events and the actions that take
- Prospective Analysis: this includes the patterns and the trends from the future for which the data is already been generated. For example, weather prediction is one of the major examples of prospective analysis. In this, there are chances that it may be misleading also (Paxton & Griffiths 2017).
3.5.2 Challenges faced in the big data analysis
- Scale: the major issue is of the size of the data. The big data has a word big in it so because of this large data many issues are faced in the decades. To cope up with the large increasing data and volume Moore’s law was used for this and also the speed for the static CPU is increased.
- Heterogeneity and Incompleteness: heterogeneity is faced by the humans when they consume information. For proper data analysis, the data should be presented in a structured form. For example: For a patient having multiple check-ups at the same hospital, creates one record and maintains that record for a lifetime. All the medical check-ups and tests are different for each patient. There are three ways in which data is presented and analysis is done. In large structure, the traditional analysis is done, so the less structured design is preferred as it is more effective than others to be used.
- Timeliness: time taken in processing of large data is longer. The system is designed such that the given input sets can process at a fast speed. Not only is the speed velocity also high for the data.
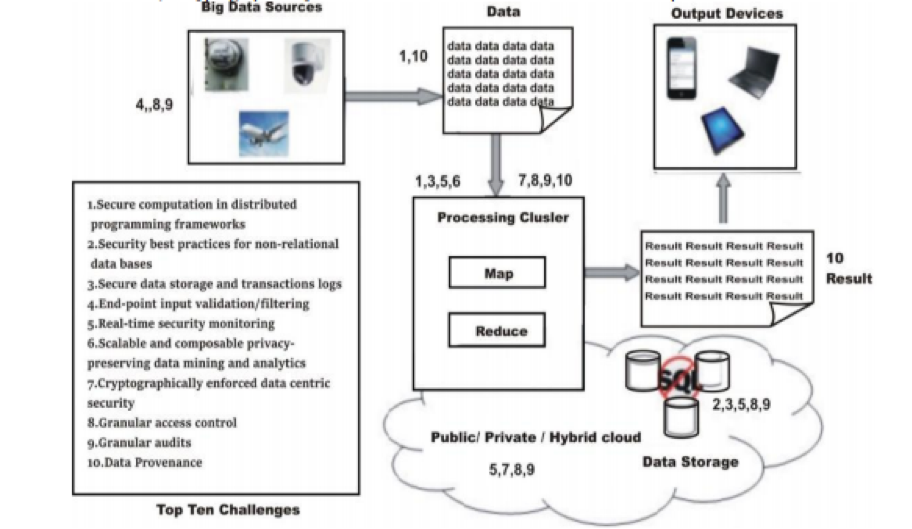
Figure 8: Top ten challenges
(Source: John Walker, 2018)
3.6 The security mechanism for big-data based on homomorphic encryption using cubic spline public key cryptography
3.6.1 Problem Statement
The protection of the data in this work is based on the asymmetric mode of encrypting data that is based on a cubic spline curve. This encryption is used for the fully harmonic encryption in the field of big data. The global variables are generated using a steady state and a one-dimensional equation that would be integrated into the control volume. The public keys are calculated from these global variables from the chosen private keys (Krishna 2018). After getting the public and private keys, the security mechanism is provided for the big data using these keys. The Homomorphic encryption is the extension of this mechanism in which the addition, subtraction and other arithmetic operations would be done using the ciphertexts without damaging the integrity of the ciphertexts. Therefore, the study presents advantages of securing data that is saved in the cloud of the public domain.
3.6.2 Asymmetric encryption
The study covers three coding modes namely error correcting codes, data compression, and cryptography. It mainly is dealing with the conversion of information to an unidentified form so that the private security can be provided from the unauthorized users (Wamba et al. 2015). The study presents the two modes for encryption: symmetric and asymmetric encryption. Symmetric encryption lets one key to be being used by the party that participates that can provide the security, but the authentication is indirect. Whereas in asymmetric encryption, two keys are used by each user which will help in security as well as direct authentication. The two important algorithms used in the asymmetric encryption are RSA and ECC. The private key is used in the symmetric encryption so that the data can be transferred with security. In this study, the timestamp is used by the authors that will be used to provide the security at the low-level computing sources. The non-linear features are incorporated in the model to refine the security of the model. This study helps in identification of the relevance in the real-time environment of the asymmetric encryption (Krishna 2018). This study also analyses the benefits of numerical analysis to build a mathematical model.
The homomorphic encryption is used to help in the execution of the arithmetic operation such as multiplication and the addition on the ciphertext in a way so that the integrity of the model is not harmed by the algorithm. The secure design of the homomorphic encryption provides a method of securing the data in public domains like cloud servers. The cloud computing model is represented by the nodes that are presented in this study (Krishna 2018). The roles of the nodes like input, computing, output, and input are used to categorize the nodes. The enrichment nodes support the architecture of the cloud environment whose purpose is to refine the data based on a feedback from the user. The architecture of the big data has the support of the big-data ecosystem as the central point where all the data sources are linked to the one end to the other link the applications. The foundation of the architecture is constituted by the security, information governance and business continuity (Krishna 2018).
The security in the cloud is necessary as a huge amount of storing data in the servers that are not safe from attackers as the data is always connected to the internet. This can make the data and the cloud environment vulnerable to the attack and the data theft on the cloud environment. For this purpose, a special mechanism for the encryption of the data is provided so that the protection of data can be done. The encryption of the data can be responsibly done by the encryption process. There are many encryption algorithms that could protect the data on the shared environment. As the sensitive data is shared on the third-party cloud server, the cryptography mechanism is proven to be important for protecting the data on the internet.
3.6.3 The methodology of Cubic Spline Curve based encrypting model
The interpolating model of Cubic Spline Curve is the main topic of discussion. The Analytical data on the 1D steady-state reckoning is converted to the numerical model. The seed is initiated by generating the coefficients a, b, c and d & then they are mapped to d using the tridiagonal algorithm. The numerical model is converted to the crypto model by considering the base value as d and the global variables are used to generate the private key. The random value also referred to as ciphertext is generated to create the public key (Krishna 2018). The consideration of the private key is taken, and the ciphertext is then converted from encrypted to simple text using the same algorithm. The model is developed and implemented the fully homomorphic encryption mechanism that can be verified by its adaptability in the environment.
3.6.4 Conclusion
The presented study used a cubic spline curve public key cryptography based on the numerical model that will be used to implement fully homomorphic encryption to provide the security to the big data that is present in the open and shared environment. The working model of the technique is the asymmetric block cipher mode which is very rare, and it is not commonly used. The model used very fewer computation resources in processing the ciphertexts in the algorithm that is better suited in the shared environment where the big data is stored and protected. During the construction of the algorithm, the length of the key that is needed for providing better security with enough privacy is much lesser than that is needed in the ECC algorithm. The usage of a random number for the encrypting the data during the encryption process, the process is free from the differential side channel attacks.
3.7 security issues of big data environment based on quantum cryptography and privacy with authentication for mobile data center
3.7.1 Overview
There are a plenty of the solutions available for the security of the big data which is available on the different platform of the society. The implementation of the security of big data on the cloud network (i.e. the size of more than 1 TB). The big data has been doubling for many years. Based on a research, it is estimated that 2.5 zettabytes of the information have been handled in 2012. The privacy of big data is another concern that needs to be handled using the technique of paper management. Many studies show that the Quantum cryptography has supported the generation of the authenticated key (Thayananthan and Albeshri 2015). This authenticated key is used to provide secure data through the management of key within the user and the authentication server that are associated in the data centers. The model includes the searching using the efficient key and different size key generation. The generation of keys is less complex as compared to issues of big data. The authentication has supported the privacy of the model through the efficient verification of the entities and the validation of entities. These entities are the authentication servers and mobile data users. The advanced security protocols are used where the security and the privacy of the huge amount of data are stored. The difficulty of the security mechanism is reduced by using these methods and this makes the proper creation of the dynamic security solutions. The presence of the complexity increases the traffic in the network, delay in the protocols and the storage problems in the server (Thayananthan and Albeshri 2015). This complex situation needs to be addressed and the address should be done using the efficient authentication protocols which are able to secure the data and the privacy dynamically. The trade-off is present in the complexity and the big data security along with the traffic. This trade-off during the data handling is the unavoidable center.
The big data is generated from a lot of sources as the internet is growing bigger in size each day. The continuous upload of the data on the internet has increased the amount of data that is present on the third party servers. The data is unsafe as it is continuously connected to the servers which are not safe. The internet is vulnerable to the threats from the attackers and the hackers that are present on the internet. It is very important for the data storage service providers that the data is protected from the vulnerabilities that are present on the internet. There are several ways through which the privacy and security of the data can be provided on the internet (Thayananthan and Albeshri 2015). The encryption of the data is one of the ways to protect the data easily on the third party server. Many algorithms can be used to encrypt the data. Cryptography as suggested in this study is one of the best algorithms to encrypt the data on the server with the help of providing the key generation and the management techniques to reduce the complexities and work on protecting the data dynamically over the server or the shared environment of the third party cloud server (Thayananthan and Albeshri 2015). This process is proven to be useful for the data security on the servers.
3.7.2 Proposed model methodology
The use of the authentication key will be taken to secure the authentication amongst the mobile user and the server of authentication. The proposed model ensures the validation of the security of the data with the KM organized in the mobile data centers the expectation of the authentication server is quick and more efficiency in authentication. The use of the PairHand protocol will use the proper authentication to reduce the computations and increase the efficiency of the authentication by handover.
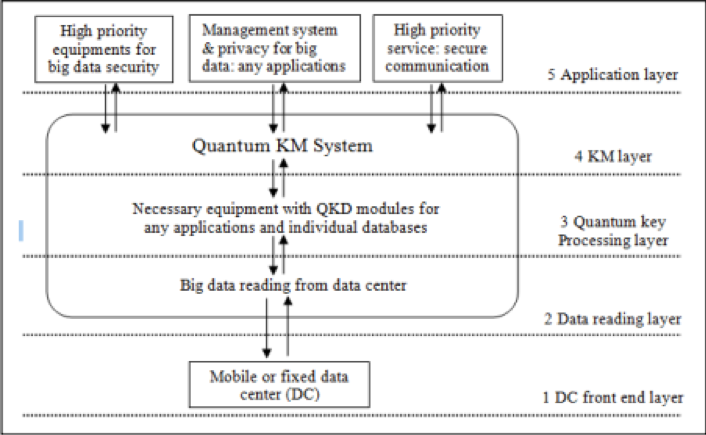
Figure 9: The theoretical model for the KM quantum system in the data center
(Source: Thayananthan & Albeshri, 2015)
The confirmations and the IDs of the mobile user and the big data are read by the theoretical model using the QC and the authentication protocols. The operation of the interface takes place and the GA is used to give the required performance to minimize the presence of complexity throughout the processing of KM. The processing of the quantum key is done. This takes place that is based on the various factors that include the quantum key distribution based on QC. The help of DC is taken so that multiple data can be taken from ports to enhance the working efficiency of the Quantum key processing (Thayananthan and Albeshri 2015). The KM protocols which are based on the QC are employed to take care of the security in the big data and traffic condition. The security of the big data is also dependent on the application for which the security is needed. The security policies are made according to the organization needs and policies.
3.7.3 Results of the research
The QC is proposed in the research with the PairHand authentication protocol that is attracted towards the mobile applications. The security in the big data and privacy of the big data is expected to every quick and efficient in the mobile data centers. The actions should be dynamic when the traffic flow is increased (Thayananthan and Albeshri 2015). The introduced model successfully proves that the security structure in the mobile data centers which uses the PairHand protocol is effective in reducing the computational complexity of the model as well as it is useful in increasing the efficiency of the authentication through handover.
Figure 10: key complexity in the security of the big data
(Source: Erevelles Fukawa & Swayne 2016)
The security of the big data is studied along with preserving the privacy of the data using QC, GA and the protocols of PairHand in the use of mobile data centers which includes TB, EB and ZB data traffic (Thayananthan and Albeshri 2015). The security of the big data on specific servers depends on the factors like data size, traffic and the Delay in data in the times when the mobile data handles the secure authentication amongst the authentication server and the mobile users. The novel design is created with the help of the factors explained in the section that affects the big data on the shared environment. The theoretical model of KM to make the authentication efficient using the QC and GA is proposed in the model. This ensures that the data is secured and the privacy is maintained of the big data on the cloud storage (Thayananthan and Albeshri 2015).
3.8 Data Security in Smart Cities: Challenges and Solutions
In the big cities the major problem faced is of organizing the big data available and also in this paper the issues related to big data is discussed and the also the problems related to the security issues and problems faced in smart cities is discussed as there are large data depositaries with the number of consumers, producers etc. It is needed that the security, privacy, management, proper standards, and architectures are needed so that it will make a proper design and proper manages is done.
Chapter 4
Conclusion
The data is growing at a large amount day by day in the worldwide as social networking sites, search engines, stock trading sites, news, and media sharing sites are increasing. Big data is becoming coming up as a new area using which data is researched and also business applications is growing. Big data analysis is used in automatic discovering of the continuous occurred pattern and the hidden rules. Big data also helps the companies for taking better decisions, for predicting and identifying the new opportunities that are knocking and the changes that are made. In this, the major security challenges of Big data is discussed related to the Big Data mining and in this also tools for Big Data analysis like Map-Reduce over Hadoop, HDFS etc. are discussed that helps the organization in understanding the customers and also understanding the customers, marketplace so that the better decisions can be taken. These help the scientists and researchers in extracting useful information and knowledge from the Big Data and for this many tools are introduced (Erevelles Fukawa & Swayne 2016).
As the computational heredities are going under the revolution. The complexity has also increased with the development of a large amount of data from numerous data generators. Due to the increment in the complexity of data maintenance, big data challenges have also occurred. Towards that there is the number of methods has been discussed in the thesis. The recognition of genuine and actual user is mandatory to keep the security and privacy of big data. The thesis includes researches and paper that assist the users to maintain the confidentiality of their critical big data and reduce the chances of false retrievals and accesses. It has also found that the current and existing data security methods are quite insecure when the security and privacy are required on the level.
Therefore, robust and sophisticated techniques and methods are required that can help to maintain data integrity and confidentiality in the big data environment. Further researched must be focused on the development of feasible and reliable big data security methods.
List of References
- Abbasi, A, Sarker, S & Chiang, RH 2016, ‘Big data research in information systems: Toward an inclusive research agenda’, Journal of the Association for Information Systems, vol. 17, 2.
- Akter, S & Wamba, SF 2016, ‘Big data analytics in E-commerce: a systematic review and agenda for future research’, Electronic Markets, vol. 26, no. 2, pp. 173-194.
- Amin, M 2015, ‘Smart Grid’, PUBLIC UTILITIES FORTNIGHTLY.
- Assunção, MD, Calheiros, RN, Bianchi, S, Netto, MA & Buyya, R 2015, ‘Big Data computing and clouds: Trends and future directions’, Journal of Parallel and Distributed Computing, vol. 79, pp. 3-15.
- Chatfield, A, Reddick, C & Al-Zubaidi, W 2015, ‘Capability challenges in transforming government through open and big data: Tales of two cities.’
- Chen, CP & Zhang, CY 2014, ‘Data-intensive applications, challenges, techniques, and technologies: A survey on Big Data’, Information Sciences, vol. 275, pp. 314-347.
- Chen, S, Xu, H, Liu, D, Hu, B & Wang, H 2014, ‘A vision of IoT: Applications, challenges, and opportunities with China perspective’, IEEE Internet of Things journal, vol. 1, 4, pp. 349-359.
- Cui, L, Yu, FR & Yan, Q 2016, ‘When big data meets software-defined networking: SDN for big data and big data for SDN’, IEEE network, vol 30, no. 1, pp.58-65.
- De Mauro, A, Greco, M & Grimaldi, M 2015, ‘What is big data? A consensual definition and a review of key research topics’, In AIP conference proceedings, vol. 1644, no. 1, pp. 97-104. AIP.
- De Mauro, A, Greco, M & Grimaldi, M 2016, ‘A formal definition of Big Data based on its essential features’, Library Review, vol. 65, 3, pp.122-135.
- Diamantoulakis, PD, Kapinas, VM & Karagiannidis, GK 2015, ‘Big data analytics for dynamic energy management in smart grids’, Big Data Research, vol. 2, no. 3, pp. 94-101.
- Dou, W, Zhang, X, Liu, J & Chen, J 2015, ‘HireSome-II: Towards privacy-aware cross-cloud service composition for big data applications’, IEEE Transactions on Parallel and Distributed Systems, vol. 26, no. 2, pp. 455-466.
- Erevelles, S, Fukawa, N & Swayne, L 2016, ‘Big Data consumer analytics and the transformation of marketing’, Journal of Business Research, vol. 69, no. 2, pp.897-904.
- Gai, K, Qiu, M, Sun, X & Zhao, H 2016, ‘December. Security and privacy issues: A survey on FinTech’, In International Conference on Smart Computing and Communication, pp. 236-247. Springer, Cham.
- Gupta, B, Agrawal, DP & Yamaguchi, S eds 2016, ‘Handbook of research on modern cryptographic solutions for computer and cyber security’, IGI Global.
- Hota, C, Upadhyaya, S & Al-Karaki, JN 2015, ‘Advances in secure knowledge management in the big data era’, Information Systems Frontiers, vol. 17, no. 5, pp. 983-986.
- Huo, Y, Sun, Y, Fan, W, Cheng, X, Li, D & Liu, Y 2017, ‘A Survey on Security Issues in Big Data of Ubiquitous Network’, In International Conference on 5G for Future Wireless Networks, pp. 89-98. Springer, Cham.
- Inukollu, VN, Arsi, S & Ravuri, SR 2014, ‘Security issues associated with big data in cloud computing’, International Journal of Network Security & Its Applications, vol. 6, 3, pp.45.
- Jain, AK, Nandakumar, K & Ross, A 2016, ‘50 years of biometric research: Accomplishments, challenges, and opportunities’, Pattern Recognition Letters, vol. 79, pp.80-105.
- Jakóbik, A 2016, ‘Big data security’, In Resource Management for Big Data Platforms, pp. 241-261. Springer, Cham.
- Jiang, L & Meng, W 2017, ‘Smartphone user authentication using touch dynamics in the big data era: Challenges and opportunities’, In Biometric Security and Privacy, pp. 163-178.
- John Walker, S 2014, ‘Big data: A revolution that will transform how we live, work, and think’.
- Kim, GH, Trimi, S & Chung, JH 2014,’ Big-data applications in the government sector’, Communications of the ACM, vol. 57, no. 3, pp.78-85.
- Kim, GH, Trimi, S & Chung, JH 2014. ‘Big-data applications in the government sector’, Communications of the ACM, vol. 57, no. 3, pp.78-85.
- Kitchin, R 2014,’The data revolution: Big data, open data, data infrastructures and their consequences’, Sage.
- La Torre, M, Dumay, J & Rea, MA 2018, ‘Breaching intellectual capital: critical reflections on Big Data security,’ Meditari Accountancy Research, vol. 26, no. 3, pp.463-482.
- Lazer, D, Kennedy, R, King, G & Vespignani, 2014, ‘The parable of Google Flu: traps in big data analysis’, Science, vol. 343, no. 6176, pp.1203-1205.
- Lee, J, Kao, HA & Yang, S 2014, ‘Service innovation and smart analytics for industry 4.0 and big data environment’, Procedia Cirp, vol. 16, pp.3-8.
- Lv, Y, Duan, Y, Kang, W, Li, Z & Wang, FY 2015, ‘Traffic flow prediction with big data: A deep learning approach’, IEEE Trans. Intelligent Transportation Systems, vol. 16, no. 2, pp.865-873.
- Manogaran, G, Varatharajan, R, Lopez, D, Kumar, PM, Sundarasekar, R & Thota, C 2018, ‘A new architecture of Internet of Things and big data ecosystem for secured smart healthcare monitoring and alerting system’, Future Generation Computer Systems, vol. 82, pp.375-387.
- Matturdi, B, Xianwei, Z, Shuai, L & Fuhong, L 2014, ‘Big Data security and privacy: A review’, China Communications, vol. 11, no. 14, pp.135-145.
- Najafabadi, MM, Villanustre, F, Khoshgoftaar, TM, Seliya, N, Wald, R & Muharemagic, E 2015, ‘Deep learning applications and challenges in big data analytics’, Journal of Big Data, vol. 2, no. 1, pp.1.
- Patil, HK & Seshadri, R 2014, ‘June. Big data security and privacy issues in healthcare,’ In Big Data (BigData Congress), 2014 IEEE International Congress on, pp. 762-765.
- Paxton, A & Griffiths, TL 2017, ‘Finding the traces of behavioral and cognitive processes in big data and naturally occurring datasets’, Behavior research methods, vol. 49, no. 5, pp.1630-1638.
- Riggins, FJ & Wamba, SF 2015, ‘January. Research directions on the adoption, usage, and impact of the internet of things through the use of big data analytics’, In System Sciences (HICSS), 2015 48th Hawaii International Conference on, 1531-1540.
- Savas, O & Deng, J 2017, Big Data Analytics in Cybersecurity, ‘Auerbach Publications’.
- Sharma, PP & Navdeti, CP 2014, ’Securing big data hadoop: a review of security issues, threats and solution’, J. Comput. Sci. Inf. Technol, vol. 5, no. 2, pp.2126-2131.
- Solanas, A, Patsakis, C, Conti, M, Vlachos, IS, Ramos, V, Falcone, F, Postolache, O, Pérez-Martínez, PA, Di Pietro, R, Perrea, DN & Martinez-Balleste, A 2014, ‘Smart health: a context-aware health paradigm within smart cities’, IEEE Communications Magazine, vol. 52, 8, pp.74-81.
- Stojmenovic, I, Wen, S, Huang, X & Luan, H 2016, ‘An overview of fog computing and its security issues’, Concurrency and Computation: Practice and Experience, vol.28, 10, pp.2991-3005.
- Sun, Y, Song, H, Jara, AJ & Bie, R 2016, ‘Internet of things and big data analytics for smart and connected communities’, IEEE access, vol.4, pp.766-773.
- Tsai, CW, Lai, CF, Chao, HC & Vasilakos, AV 2015, ‘Big data analytics: a survey’, Journal of Big Data, vol.2, 1, pp.21.
- Vatsalan, D, Sehili, Z, Christen, P & Rahm, E 2017, ‘Privacy-preserving record linkage for big data: Current approaches and research challenges’, Handbook of Big Data Technologies’, pp. 851-895
- Wamba, SF, Akter, S, Edwards, A, Chopin, G & Gnanzou, D 2015, ‘How ‘big data’can make big impact: Findings from a systematic review and a longitudinal case study’, International Journal of Production Economics, vol.165, pp.234-246.
- Wolfert, S, Ge, L, Verdouw, C & Bogaardt, MJ 2017, ‘Big data in smart farming–a review’, Agricultural Systems, vol.153, pp.69-80.
- Yi, S, Li, C & Li, Q 2015. ‘June. A survey of fog computing: concepts, applications and issues’, Proceedings of the 2015 workshop on mobile big data, 37-42.
- Yin, S & Kaynak, O 2015. ‘Big data for modern industry: challenges and trends [point of view]’, Proceedings of the IEEE, vol.103, 2, pp.143-146.
- Yu, S 2016. ‘Big privacy: Challenges and opportunities of privacy study in the age of big data’, IEEE access, vol.4, pp.2751-2763.
- Zhang, Y, Qiu, M, Tsai, CW, Hassan, MM & Alamri, A 2017. ’Health-CPS: Healthcare cyber-physical system assisted by cloud and big data’, IEEE Systems Journal, vol.11, 1, pp.88-95.